- 원문은 Anthropic의 원 글을 확인해주세요.
Context는 AI agent에게 핵심적이지만 유한한 자원입니다. 이 글에서는 agent를 구동하는 context를 효과적으로 큐레이션하고 관리하는 전략을 다룹니다.
응용 AI 영역에서 몇 년간 prompt engineering이 주목받은 뒤, 최근에는 context engineering이라는 용어가 부각되고 있습니다. 언어 모델 기반 개발은 이제 prompt에서 “어떤 문장과 표현을 쓰느냐”보다, “우리 모델이 원하는 동작을 하게 만들 가능성이 가장 높은 context 구성은 무엇이냐”를 묻는 문제로 이동하고 있습니다.
여기서 context는 대규모 언어 모델(LLM)에서 샘플링할 때 포함되는 token 집합을 뜻합니다. 엔지니어링 과제는 LLM 고유의 제약 안에서 이 token들의 효용을 최적화해 일관되게 원하는 결과를 내도록 만드는 일입니다. LLM을 잘 다루려면 결국 context 중심으로 사고해야 합니다. 즉, 특정 시점에 LLM이 볼 수 있는 전체 상태와 그 상태가 어떤 동작을 유도할 수 있는지를 함께 고려해야 합니다.
이 글에서는 context engineering이라는 떠오르는 실천을 살펴보고, 조정 가능하고 효과적인 agent를 만들기 위한 더 정교한 사고 모델을 제시합니다.
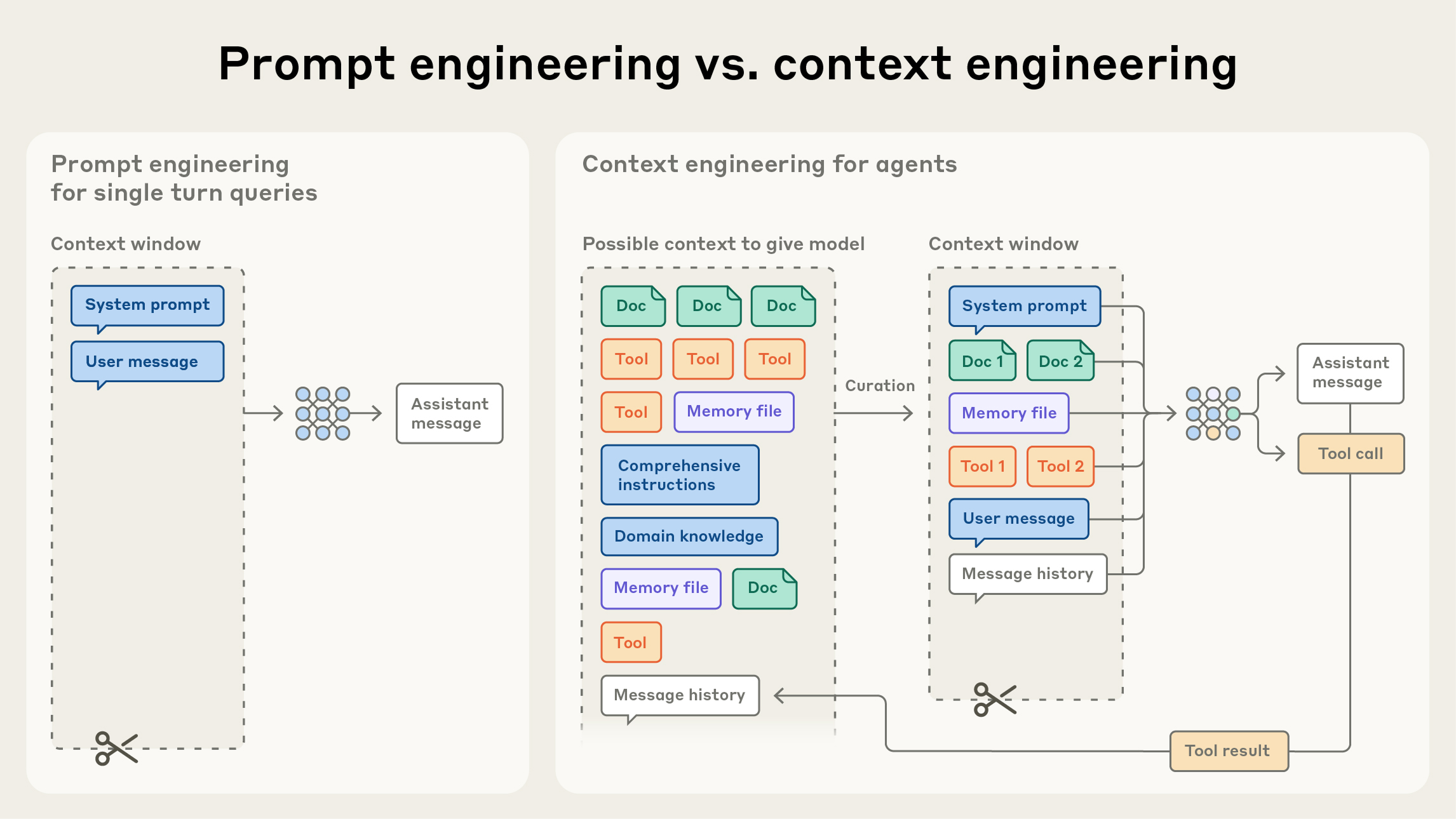
Context engineering vs. prompt engineering
Anthropic에서는 context engineering을 prompt engineering의 자연스러운 진화로 봅니다. prompt engineering은 LLM 지시문을 작성하고 구성해 더 나은 결과를 내는 방법론을 가리킵니다(관련 문서).
context engineering은 LLM 추론 과정에서 최적 token(정보) 집합을 큐레이션하고 유지하는 전략 전반을 뜻합니다. prompt 자체뿐 아니라 prompt 바깥에서 context에 유입되는 모든 정보까지 포함합니다.
LLM 초기 엔지니어링 단계에서는 prompt가 AI 개발의 가장 큰 비중을 차지했습니다. 일상적 채팅을 벗어난 대부분의 사용 사례가 one-shot 분류나 텍스트 생성 작업이었고, 이를 위해 최적화된 prompt가 필요했기 때문입니다. 이름이 말해주듯 prompt engineering의 주된 초점은, 특히 system prompt를 어떻게 효과적으로 작성하느냐에 있었습니다.
하지만 이제 우리는 여러 번의 추론 turn과 더 긴 시간 축에서 작동하는 고도화된 agent를 설계하고 있습니다. 그래서 전체 context 상태(system instruction, tools, Model Context Protocol(MCP), 외부 데이터, message history 등)를 관리하는 전략이 필요합니다.
loop 안에서 동작하는 agent는 다음 추론 turn에 유의미할 수 있는 데이터를 계속 생성합니다. 이 정보는 순환적으로 정제되어야 합니다. context engineering은 끊임없이 변하는 정보 후보 집합에서, 제한된 context window에 무엇을 넣을지 선별하는 예술이자 과학입니다.
프롬프트를 한 번 쓰는 이산 작업과 달리, context engineering은 반복적입니다. 모델에 무엇을 넘길지 결정할 때마다 큐레이션 단계가 다시 발생합니다.
Why context engineering is important to building capable agents
LLM은 빠르고, 점점 더 큰 데이터를 다룰 수 있지만, 인간처럼 어느 시점부터는 집중력을 잃거나 혼란을 겪는 모습을 보입니다. needle-in-a-haystack 유형 벤치마크 연구에서는 context rot라는 개념이 제시됩니다. context window 안 token 수가 늘어날수록 모델이 해당 context에서 정보를 정확히 회상하는 능력이 떨어진다는 뜻입니다.
모델별로 성능 저하 곡선은 다르지만, 이런 특성은 모든 모델에서 나타납니다. 따라서 context는 한계효용이 감소하는 유한 자원으로 다뤄야 합니다. 인간에게 작업 기억 용량 한계가 있듯, LLM에도 대규모 context를 파싱할 때 쓰는 attention budget이 있습니다. 새로운 token이 추가될 때마다 이 budget은 소모되고, 따라서 LLM에 제공할 token을 더 신중히 큐레이션해야 합니다.
이런 attention 희소성은 LLM 구조적 제약에서 비롯됩니다. LLM은 transformer architecture를 기반으로 하고, 이 구조에서는 전체 context에서 모든 token이 다른 모든 token에 attention할 수 있습니다. 결과적으로 token 수가 n개일 때 n²개의 쌍대 관계가 생깁니다.
context 길이가 늘어날수록 모델은 이런 쌍대 관계를 충분히 포착하기 어려워지고, 결국 context 크기와 attention 집중 사이에 자연스러운 긴장이 생깁니다. 또한 모델은 보통 긴 시퀀스보다 짧은 시퀀스가 더 많은 학습 분포에서 attention 패턴을 익히므로, 장문 context 전반의 의존 관계를 다루는 경험과 특화 파라미터가 상대적으로 적습니다.
position encoding interpolation 같은 기법은 원래 더 작은 context로 학습된 모델을 확장해 긴 시퀀스를 다루게 해주지만, token 위치 이해 성능 저하가 일부 발생합니다. 이런 요인들은 성능이 갑자기 끊기는 절벽보다는 점진적 기울기를 만듭니다. 모델은 긴 context에서도 충분히 강력하지만, 짧은 context 대비 정보 검색 정확도나 장거리 추론 정밀도는 떨어질 수 있습니다.
이런 현실 때문에, 강력한 agent를 만들려면 정교한 context engineering이 필수입니다.
The anatomy of effective context
LLM은 유한한 attention budget 제약을 받기 때문에, 좋은 context engineering은 원하는 결과가 나올 가능성을 최대화하는 고신호 token 집합을 가능한 한 작게 찾는 일입니다. 말은 쉽지만 구현은 어렵습니다. 아래에서는 context 구성 요소별로 이 원칙이 실제로 무엇을 뜻하는지 설명합니다.
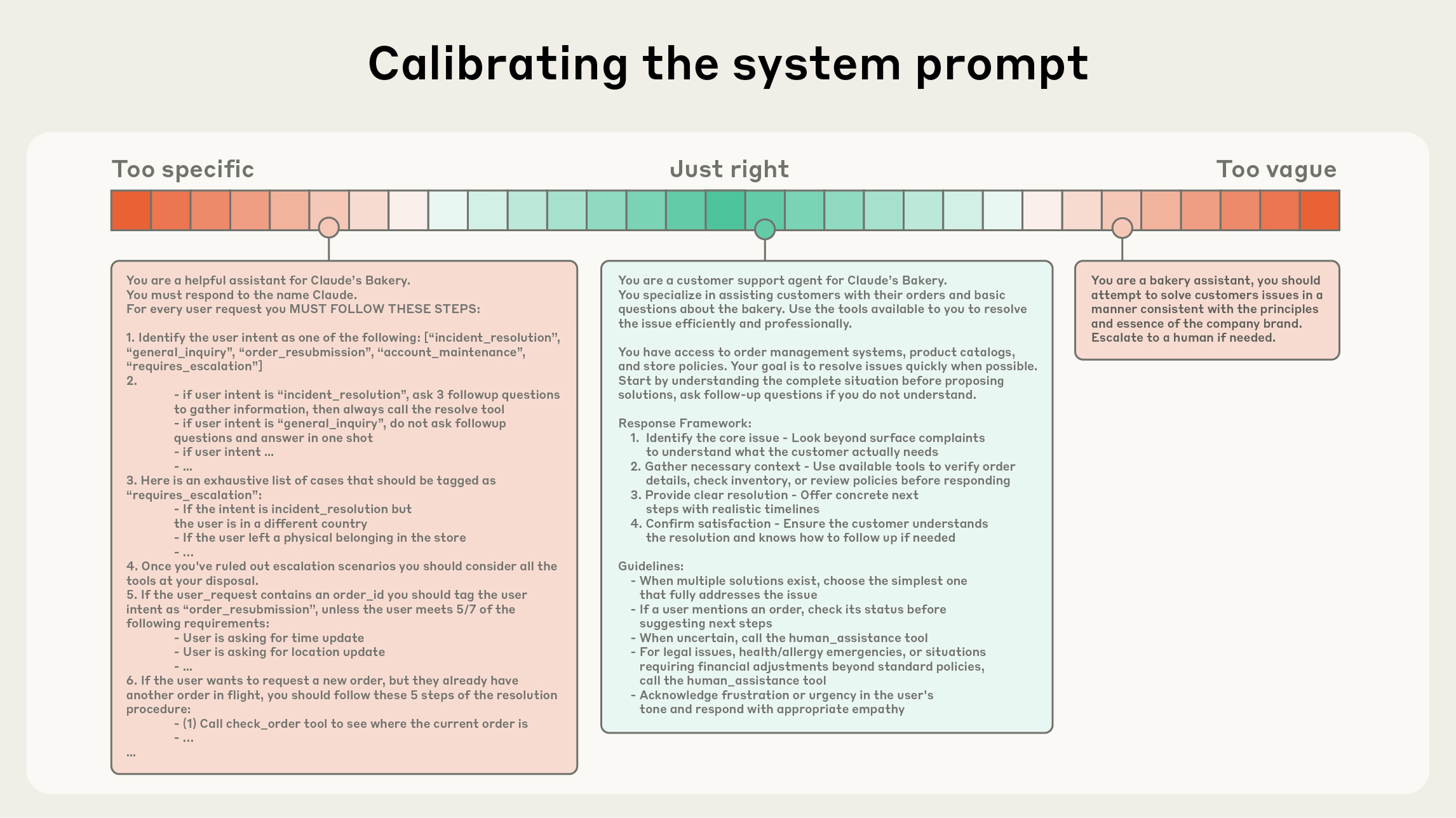
system prompt는 매우 명확해야 하고, agent에게 맞는 추상화 고도(right altitude)에서 단순하고 직관적인 언어를 써야 합니다. right altitude는 흔한 두 실패 모드 사이의 균형점입니다. 한쪽 극단에서는 엔지니어가 정확한 agent 동작을 유도하려고 prompt에 복잡하고 취약한 로직을 하드코딩합니다. 이 방식은 시스템을 깨지기 쉽게 만들고, 시간이 갈수록 유지보수 복잡도를 높입니다.
반대 극단에서는 원하는 출력에 필요한 구체 신호를 주지 못하거나, 공유 맥락이 있다고 잘못 가정한 채 추상적인 안내만 제공하기도 합니다. 최적 지점은 충분히 구체적이면서도 유연해야 합니다. 즉, 모델이 동작을 이끌 휴리스틱을 얻을 만큼 명확하면서 과도하게 경직되지는 않아야 합니다.
context engineering 과정에서 system prompt를 보정할 때도 마찬가지입니다. 한쪽에는 if-else를 하드코딩한 취약한 prompt가 있고, 다른 쪽에는 지나치게 일반적이거나 공유 맥락을 과신하는 prompt가 있습니다.
Anthropic은 prompt를 <background_information>, <instructions>, ## Tool guidance, ## Output description 같은 섹션으로 구분하고, XML 태그나 Markdown 헤더로 경계를 표시하길 권장합니다. 다만 모델 성능이 높아질수록 prompt 포맷 자체의 중요도는 점차 낮아질 수 있습니다.
어떤 구조를 택하든 핵심은 동일합니다. 기대 동작을 완전히 규정할 수 있는 최소 정보 집합을 목표로 해야 합니다.
여기서 minimal은 반드시 short를 뜻하지 않습니다. 원하는 동작을 지키게 하려면 agent에게 초기 정보는 충분히 제공해야 합니다. 가장 좋은 시작점은, 가능한 최소 prompt를 최고 성능 모델에 먼저 테스트해보고 초기 실패 모드를 기준으로 명확한 지시와 예시를 덧붙여 개선하는 것입니다.
tool은 agent가 환경과 상호작용하고 추가 context를 가져오게 해줍니다. tool은 agent와 정보/행동 공간 사이의 contract를 정의하므로, 정보 반환 token 효율성과 agent 동작 효율성을 함께 높이도록 설계하는 게 중요합니다.
Anthropic은 Writing tools for AI agents – with AI agents에서 LLM이 잘 이해하고 기능 중복이 최소화된 tool 설계를 다뤘습니다. 잘 설계된 코드베이스의 함수처럼, tool은 자기완결적이어야 하고 오류에 강해야 하며 용도가 아주 분명해야 합니다. 입력 파라미터도 설명적이고 모호하지 않아야 하며, 모델의 고유 강점을 살릴 수 있어야 합니다.
현장에서 자주 보는 실패 모드는 기능 범위가 너무 넓거나, 어떤 상황에서 어떤 tool을 써야 하는지 판단이 모호한 비대한 tool 세트입니다. 인간 엔지니어조차 특정 상황에서 어떤 tool을 써야 하는지 단정하지 못한다면, AI agent에게 더 나은 판단을 기대하기는 어렵습니다. 뒤에서 다루듯, 최소한의 실행 가능 tool 세트를 유지하면 장기 상호작용에서 context 유지/가지치기의 신뢰성도 좋아집니다.
few-shot prompting으로 알려진 예시 제공은 지금도 매우 효과적인 모범 사례입니다. 다만 팀이 task별 규칙을 빠짐없이 담겠다고 edge case를 장황하게 나열하는 경우가 많고, Anthropic은 이를 권장하지 않습니다. 대신 agent의 기대 동작을 효과적으로 보여주는, 다양하면서도 대표성이 있는 예시 세트를 큐레이션하는 것이 좋습니다.
LLM에게 예시는 “천 마디 말보다 강한 그림”입니다.
context 구성 요소(system prompt, tools, examples, message history 등) 전반에 대한 핵심 가이드는 같습니다. 맥락은 신중하게, 정보성은 높게, 하지만 타이트하게 유지해야 합니다. 이제 런타임 동적 context retrieval로 넘어갑니다.
Context retrieval and agentic search
Anthropic은 Building effective AI agents에서 LLM 기반 workflow와 agent의 차이를 설명했습니다. 그 글 이후에는 agent를 “LLM이 loop 안에서 도구를 자율적으로 사용하는 구조”로 정의하는 간단한 관점을 더 선호하게 됐습니다.
고객과 협업하면서 이 단순한 패러다임으로 업계가 수렴하는 흐름을 확인했습니다. 기반 모델이 더 강력해질수록 agent의 자율성 수준도 함께 확장됩니다. 더 똑똑한 모델은 미묘한 문제 공간을 스스로 탐색하고 오류에서 복구할 수 있습니다.
또한 agent context 설계 방식도 바뀌고 있습니다. 오늘날 많은 AI-native 애플리케이션은 추론 전 임베딩 기반 retrieval로 중요한 context를 끌어옵니다. 여기에 더해, 업계가 agentic 접근으로 이동하면서 “just in time” context 전략을 결합하는 사례가 늘고 있습니다.
“just in time” 접근은 관련 데이터를 전부 선처리하지 않습니다. 대신 경량 식별자(파일 경로, 저장된 쿼리, 웹 링크 등)를 유지하고, runtime에 tool로 참조 대상을 동적으로 로드합니다. Anthropic의 agentic coding 솔루션인 Claude Code는 이 방식을 써서 대규모 데이터베이스에 대한 복잡한 데이터 분석을 수행합니다.
모델은 정밀 쿼리를 작성하고, 결과를 저장하며, head, tail 같은 Bash 명령으로 대량 데이터를 분석할 수 있습니다. 전체 데이터 객체를 context에 통째로 올릴 필요가 없습니다. 이 방식은 인간 인지와 유사합니다. 우리는 보통 모든 정보를 암기하지 않고, 파일 시스템/받은편지함/북마크 같은 외부 정리·인덱싱 체계로 필요할 때 정보를 꺼내 씁니다.
저장 효율 외에도, 이런 참조의 메타데이터는 동작 정제를 위한 효율적 메커니즘을 제공합니다. 명시적으로 제공된 경우든 직관적으로 해석되는 경우든 마찬가지입니다.
예를 들어 파일 시스템에서 동작하는 agent에게 tests 폴더의 test_utils.py와 src/core_logic/의 동일 파일명은 서로 다른 의미를 암시합니다. 폴더 계층, 네이밍 규칙, 타임스탬프는 인간과 agent 모두가 정보를 언제 어떻게 써야 할지 이해하게 돕는 중요한 신호입니다.
agent가 스스로 탐색하고 데이터를 가져오게 하면 progressive disclosure도 가능해집니다. 즉, 탐색을 통해 관련 context를 단계적으로 발견할 수 있습니다. 매 상호작용은 다음 결정을 위한 맥락이 됩니다. 파일 크기는 복잡도를 암시하고, 네이밍 규칙은 목적을 시사하며, 타임스탬프는 관련성의 대리 신호가 될 수 있습니다.
agent는 이해를 층층이 조립하고, 작업 기억에는 꼭 필요한 것만 유지하면서 추가 영속성은 노트 작성 전략으로 보완할 수 있습니다. 이렇게 self-managed context window를 쓰면 포괄적이지만 불필요할 수 있는 정보에 파묻히지 않고 관련 하위 집합에 집중할 수 있습니다.
물론 trade-off는 있습니다. runtime 탐색은 사전 계산 데이터를 가져오는 방식보다 느립니다. 게다가 LLM이 정보 지형을 효과적으로 탐색하게 하려면 적절한 tool과 휴리스틱을 갖추도록 신중한 설계가 필요합니다. 가이드가 부족하면 agent는 tool을 잘못 사용하거나, 막다른 길을 추적하거나, 핵심 정보를 놓치면서 context를 낭비할 수 있습니다.
일부 환경에서는 하이브리드 전략이 가장 효과적일 수 있습니다. 속도를 위해 일부 데이터는 upfront로 가져오고, 추가 탐색은 agent가 필요하다고 판단할 때 자율적으로 수행하게 하는 방식입니다. 자율성의 적정 경계는 task 특성에 따라 달라집니다.
Claude Code도 이 하이브리드 모델을 사용합니다. CLAUDE.md 파일은 upfront로 단순히 context에 넣고, glob, grep 같은 primitive로 환경을 탐색하며 파일을 just-in-time으로 불러옵니다. 이 방식은 stale indexing이나 복잡한 syntax tree 문제를 효과적으로 우회합니다.
법률/금융처럼 비교적 동적 변화가 적은 맥락에서는 하이브리드 전략이 특히 잘 맞을 수 있습니다. 모델 역량이 향상될수록 agent 설계는 “똑똑한 모델이 똑똑하게 행동하게 둔다”는 방향으로, 사람의 큐레이션 비중을 점차 줄이는 쪽으로 갈 가능성이 큽니다. 빠르게 변하는 이 분야에서 Claude 기반 agent를 만드는 팀에게는 결국 “작동하는 가장 단순한 해법부터 적용하라”는 조언이 여전히 유효합니다.
Context engineering for long-horizon tasks
long-horizon task에서는 agent가 token 수가 LLM context window를 넘는 긴 행동 연쇄에서도 일관성, 맥락, 목표 지향 동작을 유지해야 합니다. 대규모 코드베이스 마이그레이션이나 포괄적 리서치처럼 수십 분에서 수시간 지속되는 작업에는 context window 한계를 우회하기 위한 특화 기법이 필요합니다.
더 큰 context window를 기다리는 전략은 직관적으로 보이지만, 가까운 미래에도 모든 크기의 context window는 context 오염과 정보 관련성 문제에 계속 노출될 가능성이 큽니다. 최소한 최고 수준 agent 성능이 필요한 상황에서는 그렇습니다.
Anthropic은 이런 제약을 직접 다루기 위해 compaction, structured note-taking, multi-agent architecture라는 세 가지 기법을 발전시켜 왔습니다.
Compaction
compaction은 context window 한계에 가까워진 대화를 요약하고, 그 요약으로 새 context window를 다시 시작하는 실천입니다. 보통 장기 일관성을 높이기 위한 첫 번째 레버로 작동합니다. 핵심은 context window 내용을 높은 fidelity로 압축해, agent가 성능 저하를 최소화한 채 계속 작업하게 만드는 데 있습니다.
예를 들어 Claude Code는 message history를 모델에 넘겨 가장 중요한 세부를 요약·압축하게 합니다. 모델은 아키텍처 결정, 미해결 버그, 구현 디테일은 보존하고 중복 tool 출력이나 메시지는 제거합니다. 이후 agent는 이 압축 context와 최근 접근한 파일 5개를 함께 사용해 작업을 이어갑니다. 사용자는 context window 한계를 의식하지 않아도 작업 연속성을 얻습니다.
compaction의 핵심 난점은 무엇을 남기고 무엇을 버릴지 선택하는 일입니다. 너무 공격적으로 압축하면, 나중에야 중요성이 드러나는 미묘하지만 핵심적인 맥락을 잃을 수 있습니다. compaction 시스템을 구현하는 엔지니어에게는 복잡한 agent trace 기반으로 prompt를 세밀하게 튜닝할 것을 권장합니다.
우선 recall을 최대화해 trace 내 관련 정보를 빠짐없이 포착하게 하고, 이후 불필요한 내용을 제거해 precision을 높이는 방향으로 반복 개선하는 것이 좋습니다.
쉽게 줄일 수 있는 불필요 정보의 대표 예는 tool call/result 정리입니다. 히스토리 깊은 곳에서 이미 실행된 tool의 raw 결과를 agent가 다시 볼 필요는 많지 않습니다. 가장 안전하고 가벼운 compaction 방식 중 하나가 tool result clearing이며, 최근 Claude Developer Platform 기능으로도 출시됐습니다.
Structured note-taking
structured note-taking(또는 agentic memory)은 agent가 context window 바깥 메모리에 정기적으로 노트를 기록하고, 필요 시 그 노트를 다시 context window로 가져오는 기법입니다.
이 전략은 낮은 오버헤드로 지속 메모리를 제공합니다. Claude Code가 to-do list를 만들거나, 커스텀 agent가 NOTES.md 파일을 유지하는 방식처럼 단순한 패턴만으로도 복잡한 작업 전반의 진행 상태를 추적할 수 있습니다. 수십 번의 tool call 사이에서 사라지기 쉬운 핵심 맥락과 의존성을 붙잡아 두는 데 유용합니다.
Claude playing Pokémon는 코딩 외 영역에서도 memory가 agent 역량을 어떻게 바꾸는지 보여줍니다.
이 agent는 수천 단계 게임 진행에서 목표를 정밀하게 집계합니다. 예컨대 “지난 1,234 스텝 동안 Route 1에서 포켓몬을 훈련했고, Pikachu가 목표 10레벨 중 8레벨을 올렸다” 같은 상태를 유지합니다. memory 구조에 대한 추가 prompt가 없어도, 탐색한 지역 지도를 만들고, 해금한 핵심 업적을 기억하며, 상대별로 어떤 공격이 유효한지 학습하는 전투 전략 노트를 축적합니다.
context reset 이후에도 agent는 자기 노트를 읽고 수시간 단위 훈련 시퀀스나 던전 탐색을 계속합니다. 요약 단계가 여러 번 지나도 유지되는 이런 일관성 덕분에, 정보를 LLM context window 안에만 둘 때는 불가능한 long-horizon 전략이 가능해집니다.
Anthropic은 Sonnet 4.5 출시와 함께 Claude Developer Platform 공개 베타로 memory tool도 내놓았습니다. 파일 기반 시스템으로 context window 밖 정보를 저장/조회하기 쉽게 만들어, agent가 시간에 따라 지식 베이스를 쌓고 세션 간 프로젝트 상태를 유지하며 모든 정보를 context에 상주시키지 않고도 이전 작업을 참조하게 해줍니다.
Sub-agent architectures
sub-agent architecture는 context 한계를 우회하는 또 다른 방법입니다. 하나의 agent가 전체 프로젝트 상태를 모두 유지하려 하기보다, 특화 sub-agent가 깨끗한 context window에서 집중 작업을 수행합니다. 메인 agent는 고수준 계획을 조율하고, sub-agent는 심층 기술 작업이나 tool 기반 정보 탐색을 맡습니다.
각 sub-agent는 수만 token 이상을 써가며 깊게 탐색할 수 있지만, 최종적으로는 보통 1,000~2,000 token 수준의 응축된 요약만 반환합니다.
이 접근은 역할 분리를 명확히 만듭니다. 상세 탐색 맥락은 sub-agent 안에 격리되고, 리드 agent는 결과 종합과 분석에 집중합니다. 이런 패턴은 How we built our multi-agent research system에서 소개됐고, 복잡한 리서치 과제에서 단일 agent 시스템 대비 유의미한 성능 향상을 보였습니다.
어떤 접근을 선택할지는 task 특성에 따라 다릅니다. 예를 들면 아래와 같습니다.
- compaction은 많은 왕복 대화가 필요한 작업에서 대화 흐름 유지에 유리합니다.
- note-taking은 명확한 마일스톤이 있는 반복 개발 작업에 특히 적합합니다.
- multi-agent architecture는 병렬 탐색 효과가 큰 복잡 리서치/분석 작업에서 강점이 있습니다.
모델 성능이 계속 향상되더라도, 장시간 상호작용에서 일관성을 유지하는 문제는 더 효과적인 agent를 만드는 데 계속 핵심 과제로 남을 것입니다.
Conclusion
context engineering은 LLM 기반 시스템을 구축하는 방식 자체를 바꾸는 근본적 전환입니다. 모델이 강력해질수록 과제는 “완벽한 prompt 작성”에만 있지 않습니다. 매 단계마다 모델의 제한된 attention budget에 어떤 정보를 넣을지 세심하게 큐레이션하는 일이 더 중요해집니다.
long-horizon task를 위한 compaction을 구현하든, token 효율적인 tool을 설계하든, agent가 환경을 just-in-time으로 탐색하게 하든, 원칙은 같습니다. 원하는 결과가 나올 가능성을 최대화하는 고신호 token의 최소 집합을 찾아야 합니다.
이 글에서 소개한 기법은 모델이 발전함에 따라 계속 진화할 것입니다. 이미 더 똑똑한 모델일수록 덜 규정적인 엔지니어링만으로도 agent가 더 큰 자율성을 발휘할 수 있다는 점이 드러나고 있습니다. 하지만 역량이 계속 확장되더라도, context를 소중하고 유한한 자원으로 다루는 일은 신뢰할 수 있고 효과적인 agent를 만드는 핵심으로 남을 것입니다.
지금 Claude Developer Platform에서 context engineering을 시작해보고, memory and context management cookbook에서 실전 팁과 모범 사례를 확인해보세요.
Acknowledgements
이 글은 Anthropic Applied AI 팀의 Prithvi Rajasekaran, Ethan Dixon, Carly Ryan, Jeremy Hadfield가 작성했고, Rafi Ayub, Hannah Moran, Cal Rueb, Connor Jennings가 기여했습니다. Molly Vorwerck, Stuart Ritchie, Maggie Vo의 지원에도 감사드립니다.